If you're an engineer and you're reading this, chances are you've felt pain around deploying changes to production. Deployments cause stress and anxiety for everyone involved, especially when they're an infrequent occurrence.
First, let's look at how a hypothetical team working on a financial app at a large company deploys code to production:
The team schedules a release for the end of the month, followed by a two-week code freeze.
After scheduling the release, they kick off a formal change approval process, which requires coordination across multiple teams and departments. The app has a wide range of dependencies since it integrates with other core systems.
During the release process, they uncover several features that are not production-ready. These features are delayed until the next release. They identify one critical feature that must go into the release this month, so the team works overtime and cuts a few corners to finish it.
They deploy a release candidate to a staging environment for testing. Environments are frequently in contention, so the team is blocked while they wait on servers.
After they validate that the release meets all functional and non-functional requirements, they start a manual deployment process, which means taking the application down for a few hours.
The first manual deployment fails, so they have to start over. After the deployment is successful, they monitor the release.
Now, let's say they discover performance issues with the release. They can either manually provision more resources to handle the increased load, perform a hotfix, or roll back the release entirely. Rolling back the release is a lengthy, manual process, and the SLA to provision new infrastructure is too long, so multiple engineers work on a hotfix over the weekend. Those engineers end up working a 12-day workweek. The release is tacked onto a history of failed releases, which erodes trust with management. More manual approval steps are added to catch bad deployments, which will slow down future releases.
Now, let's look at how deployments work for a hypothetical high-performing team working on a Ruby on Rails app:
A developer plans a release and coordinates with the approval of a peer. Releases are continuous, so developers are empowered to release their changes on-demand.
Since the team makes frequent use of feature flags, the mainline is always releasable. The developer is not blocked by any merged features that are not production-ready.
They spin up a staging environment and run automated tests. Environment creation and teardown is automated with Kubernetes and scripted GitHub Actions.
After all tests pass and they validate their changes, they deploy to production. Promoting the release to production is instantaneous and fully-automated.
They can automatically roll back the release in seconds if anything goes wrong. In the case of performance spikes, Kubernetes nodes automatically scale to meet the demand.
When it comes to release schedules, teams fall along a spectrum. While some apps benefit from moving at a slower pace for stability, faster is generally better for both not only the business, but also the psychological safety of engineers. In its 2020 Big Code Report, Sourcegraph found that 88% of software development teams feel anxiety during every release.
There is an irony behind the first hypothetical team working on a financial app. To enforce stability, more steps were added to the release process, which actually make it harder to deploy, and as a result, deployments happen less frequently. These large, backed-up deployments pose a greater risk for production incidents, and developers feel that pain. Things get scarier when they're less frequent.
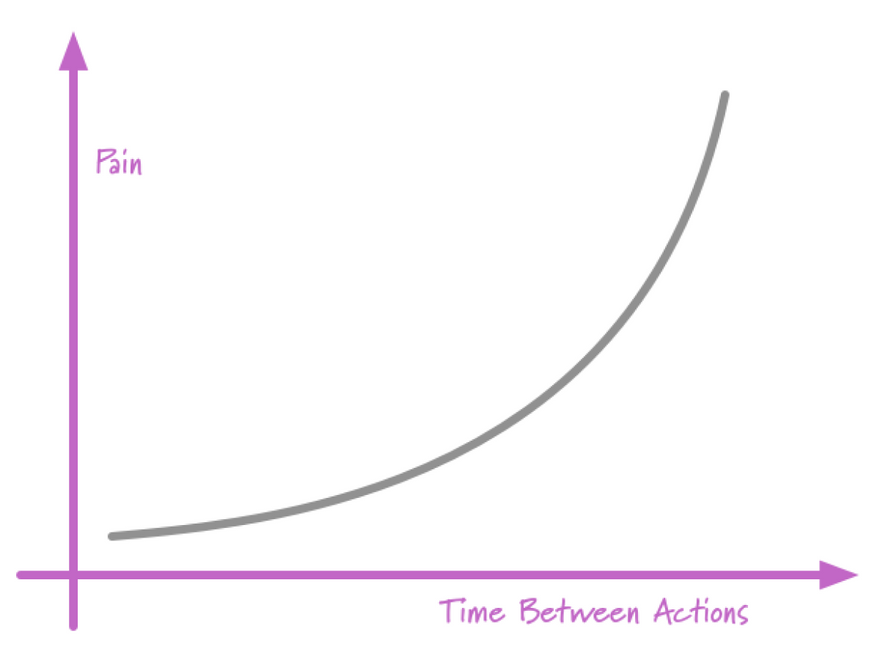
By making deployments mundane and doing them more often, teams can minimize the fear and difficulty of releasing to production. As Martin Fowler puts it: "By integrating every day, the pain of integration almost vanishes. It did hurt, so you did it more often, and now it no longer hurts."
Ways to minimize deployment pain
By aiming to make deployments faster and more frequent, teams can minimize the pain they feel when pushing their changes live.
Frequent deployments require less coordination between teams trying to get their changes into production, making releases safer and less complex. In turn, when deployments are safer and simpler, teams feel comfortable deploying more frequently. Unlocking this feedback loop is the key to achieving continuous deployment.
Measure deployments
Teams can benchmark their performance against industry standards and against themselves. The important thing is to constantly gather data and feed it back into the system to drive continuous learning.
Most teams now set up agents to monitor applications and infrastructure, using tools like DataDog, New Relic, and Sentry. These are table stakes for teams who need real-time data on any possible bugs or issues after a release.
Teams can augment their existing analytics instrumentation by measuring how changes move through their CI/CD pipelines. They can measure:
Deployment Frequency: how frequently changes are deployed to production
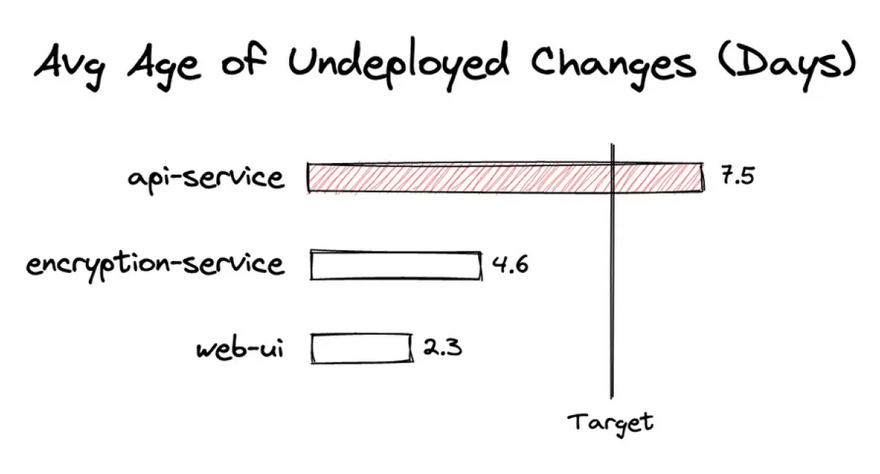
Age of Unmerged Changes: average time since a pull request has been open, but not yet deployed
Deployment Batch Size: average number of code changes per deployment
Deployment Success Rate: number of successful deployments vs. the total over time
By measuring the Age of Unmerged Changes, or how long changes are in a "Ready to Deploy" state, teams can stay on top of how much time has passed between deployments and better manage their release backlog.
Deployment Batch Size also helps teams keep track of how big the backlog is getting. Deployments should be small if they are frequent, and introducing fewer changes in each deployment helps decrease the risk of errors.
Developers working on automation and scripting can also track Deployment Success Rate and aim for a success rate above 99% for deployments to production.
Automate deployments
Fast releases require teams to remove as much manual work as possible when deploying. Engineers shouldn't need to fiddle with scripts or commands every time they want to release their changes. It slows them down and opens the door to human error. Nick Moore of Sourcegraph argues that "without automation, you're reliant on the heroics of individual engineers, which isn't scalable."
Releases should be predictable, safe, and repeatable — in other words, uneventful. Most teams are familiar with a baseline of automation. The rise of automated CI/CD tools — from Vercel to Jenkins to GitLab — has made packaging your team's changes and deploying them dead-simple.
As teams scale, they should look to take their abilities further. One option is to lean into a principle known as "Everything as Code," which requires as much of their deployment tooling to be codified as possible. GitLab enshrines this idea in their company handbook:
Deployment tooling, including pipelines, infrastructure, environments, and monitoring tools, are constantly evolving. If they can be stored as code and version-controlled, it will enable organizations to more effectively collaborate and avoid costly mistakes.
When deployments are described in code, they can be managed, replicated, and built upon by every developer on a team. It also sets the foundation for building out an internal developer platform — think self-service library of toolchains, workflows, and infrastructure — which allows teams to spin up and tear down environments on their own.
Reduce co-dependencies
When changes to a codebase require a lot of handoffs and coordination, it makes it harder to deploy even small updates. Deployments are also slowed when they impact many different parts of a codebase. Decoupling architectures and making ownership of services clear can help reduce these co-dependencies.
A loosely-coupled architecture, according to The DevOps Handbook, is one in which "services can update in production independently, without having to update other services." Microservices are one way to decouple architecture, as long as services are independent of each other. But microservices can sometimes introduce more complexity and slow things down, making it important to measure Deployment Frequency. Some teams choose to break off only a few services from their monolith to get the best of both worlds.
Some teams have reduced ambiguity by introducing a developer portal, like OpsLevel or Backstage. These tools create a catalog of services by pulling together the tools and documentation needed to use them.
Follow your code
When developers hand off their changes to deployment teams, they miss out on an important feedback loop. They can't see how their changes are working or if there were any hiccups when deploying them.
It also leads to badly aligned incentives. Without any communication between them, developers try to push code through as quickly as possible, while Ops teams try to keep the lights on. Development thinks there's a speed problem, but Ops thinks there's a quality problem.
One solution is for developers to follow their changes all the way through to production. Teams can set up notifications in Slack to alert authors when their pull request is being released to production, so they can validate and watch their changes go live. The status of merged pull requests -- and whether they are deployed or not -- can also be made visible to everyone. Developers should also have access to test suites in the deployment pipeline, monitors in production environments, and feature flags.
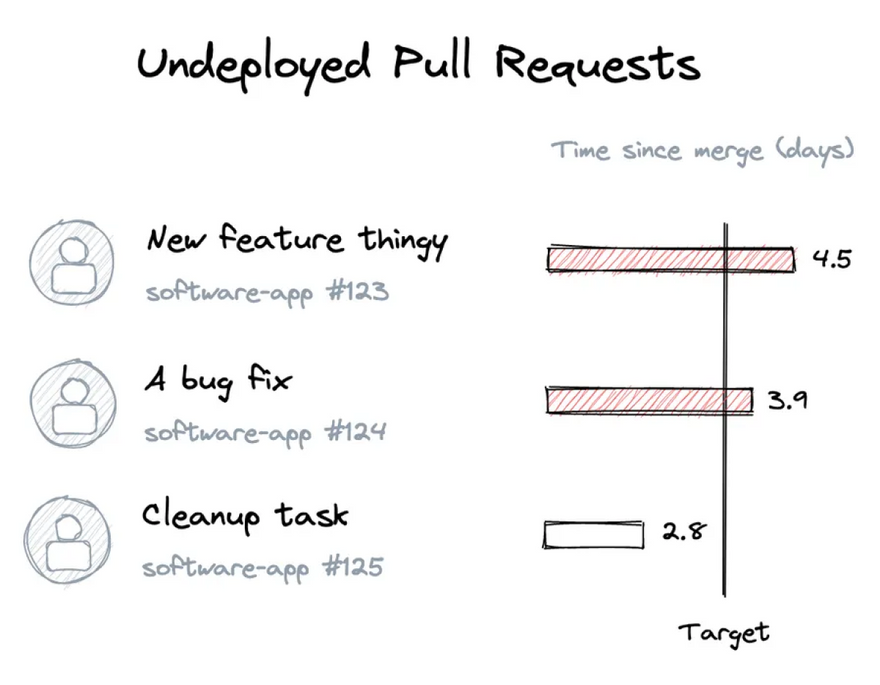
Deployments should be the opposite of a black box. When developers can see how their code flows through CI/CD pipelines, they can take those learnings back to the beginning when they start writing their next line of new code.
Make deployments progressive
Big releases can be stressful when they push out changes to many customers at once or make changes to vital systems, like a database or API.
By using progressive delivery techniques, such as feature flags, canary release, and rolling deployments, teams can lower the stakes of every deployment. These strategies reduce anxiety during releases by gradually introducing new changes into a production environment, giving teams time to make sure everything works as expected.
The DevOps Handbook describes progressive deployments as an important way to fight fear:
Instead of firefighting for days or weeks to make the new functionality work, we merely change a feature toggle or configuration setting. This small change makes the new feature visible to ever-larger segments of customers, automatically rolling back if something goes wrong. As a result, our releases are controlled, predictable, reversible, and low stress.
Using feature flags ensures that the main branch is always releasable. Teams can put work behind a feature flag until it's ready to release, which allows them to test their work in their continuous integration pipeline without blocking a deployment. During a release, they can turn on the new feature for progressively larger groups of users, gaining confidence at each step that their changes work properly.
Orchestrate an automatic release process
If releases feel chaotic or stressful, teams can try coordinating them with some lightweight automation. In Slack, they can notify authors when a PR is queued up for a release or if checks fail during a deployment. Most CI/CD tools offer Slack integrations — such as Jenkins CI, CircleCI, and Travis CI — to automatically add context.
Once changes have been deployed, monitoring gives developers confidence that a release can be undone if there is a catastrophic issue in production. If teams detect any problems, the ability to perform automatic rollbacks, fast forward fixes, or environment freezes also enables organizations to be more in control.
For example, the Slack engineering team schedules its deploys at regular intervals and puts a team member in charge to make sure everything runs smoothly:
Every day, we do about 12 scheduled deploys. During each deploy, an engineer is designated as the deploy commander in charge of rolling out the new build to production. This is a multistep process that ensures builds are rolled out slowly so that we can detect errors before they affect everyone. These builds can be rolled back if there is a spike in errors and easily hotfixed if we detect a problem after release.
Core to Slack's playbook is the ability to find problems early and take action quickly. If teams can see issues with a deployment, but can't rollback or hotfix it, they're stuck on a runaway train. Conversely, if they can quickly push out fixes, but can't spot an issue until it's affecting a lot of users, much of the damage has already been done.
Keep experimenting
Like with code reviews, there are many experiments teams can run to see what works best for their deployment process. With modern tools like GitHub Actions and CircleCI, teams have more control over how and when they deploy.
What tools does your team use for faster, safer deployments? What workflows have improved them the most?

Top comments (0)