
In 2018 Dr. Nicole Forsgren et al. introduced Accelerate: The Science of Lean Software and DevOps, a fundamentally scientific approach to figuring out how software best delivers value into an organization.
I consider it a milestone for our industry because it relies on rigorous scientific models to come to robust, scientifically validated conclusions. It's not just another self-help book based on someone who was lucky to work somewhere successful and looked for patterns that might or might not explain that success, instead Accelerate is a book that spent years collecting data and refining (and rejecting!) hypotheses, to draw out a reliable set of fascinating conclusions.
The organization behind the book, DORA (DevOps Research and Assessment) was later bought by Google, and today the research is used in yearly Accelerate State of DevOps Reports that come out with the latest round of data and refined models for measuring software impact. These reports are used by many organizations to optimize their software delivery, so it's very impactful. At this point the research sits on 7+ years of data and several tens of thousands of datapoints so it's highly reliable.
I wanted to write about what Accelerate teaches us for three reasons:
- To this day I come across lots of people who haven't read Accelerate, and I hope I can spread the word a bit by writing about it
- Even if you have read it, I think it can be useful to hear different takes on a topic even when I don't add anything new, because my takeaways and phrasings might be divergent enough to spark new creative thoughts and insights in you
- Writing blogs and presentations help me think more clearly so I'm subjecting you to this in order that I may learn the topic better 😅
But first a caveat: Accelerate is based on scientific techniques that I'm going to almost entirely skip explaining, in part because it's more interesting to talk about its practical conclusions, and in part because I'd get all the details wrong if I tried to explain statistical inferential analysis 🤯. But the most typical feedback I get when discussing this research is a skeptical "But how can they know?", especially where the research finds causative relationships. Yes, the research is rigorous enough to not just imply correlation, and that can be a hard pill to swallow for some. If you do find yourself skeptical then please know that that is a fine and understandable position, and I urge you to read the book because it goes into great depth on how they validated and rejected various theories, why their sample-size really is representative, and which levels of analyses they performed to reach their conclusions.
For now I ask if we can simply agree to trust the research well enough to proceed discussing the good stuff? The book builds up a series of statistically validated models which we need to understand and appreciate to make sense of its findings, and we can't do that if you don't believe or understand how those models were identified in the first place. When the research speaks of a model it really means they've labeled a group of well-defined properties, and then those models can be shown to positively impact other clumps of properties (i.e. other models). A model is therefore precise enough to be measured, meaning it allows us to have very precise discussions on how to improve. Here's a small, isolated example of three models:

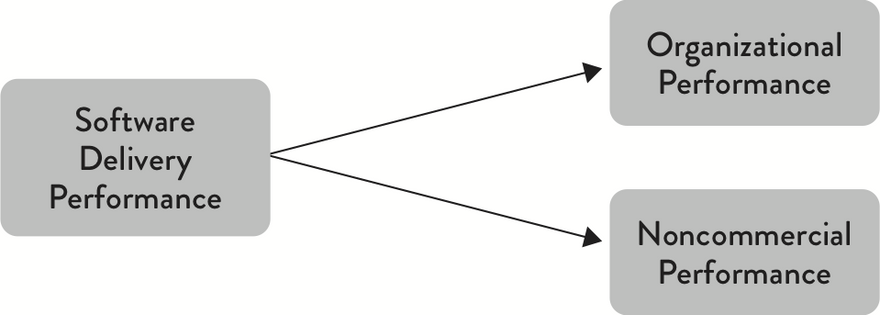
These three models are linked with arrows, and those arrows mean the Software Delivery Performance model causes improvements to the Organizational Performance model and Noncommercial Performance model. And they do mean causes, not correlates.
(Note that the full research is much bigger, with many more models and many more details for each model, but I wanted to use this simplified snippet to introduce the research's vocabulary)
With this we can now target a model we want to improve and "walk backwards" until we reach a model with properties we can tune directly. So in this case, if we want to improve Organizational Performance (and who doesn't?!), we should look into improving the Software Delivery Performance model.
Does that make sense? I know this is all very high-level and abstract, and we will dive in and get more specific soon, but we need to agree on the basic building blocks of the research to be able to state why we should care about any of this at all.
Why is this important or relevant to me?
Here's the bottomline: Teams that rank high in the Software Delivery Performance model are twice as likely to exceed organizational goals, measured against properties such as profitability, productivity, operation efficiency, number of customers, achieving missions goals, customer satisfaction, and so on. Twice as likely! And there are improvements to other important high-level models such as Job Satisfaction and Less Burnout, meaning this research is relevant to earn more money and make it more enjoyable to do so. Who can say no to that?
So that's why we should care. Remember, these aren't frivolous claims, they're the product of hard data and scientific thinking. As we dive into the details of the research's findings you can always go back to this section to realign to why we're reading and caring about this at all.
Next, let's talk about the Software Delivery Performance model in greater detail.
Photo by Marc Sendra Martorell on Unsplash. Article originally published on dev.to

Oldest comments (0)