I've spoken with countless engineering teams who have struggled with code reviews. One of the most common sentiments I've heard is that completing thorough code reviews in a reasonable timeframe while balancing other tasks can be difficult, but there are a lot of things that can go wrong.
Here's an example of an inefficient code review process:
A developer is assigned a task in Jira. The task has some ambiguity, but they start working on the task anyway.
After they complete the task, they submit a pull request and request reviewers.
The pull request is large and complex due to the requirements of the Jira issue. The reviewer decides to continue what they're working on and come back to it tomorrow. The developer is unable to make progress on their next task because it is dependent on the pull request in review.
The reviewer finally gets around to reviewing the pull request and leaves a long list of comments. Paralyzed by the number of changes requested, the developer procrastinates on making the changes and works on a new task for another project.
The developer comes back to the pull request the next day, makes the changes, and requests a re-review. They need at least one approval before they can merge.
A couple days have passed since the initial review, so the reviewer has to re-immerse themself in the context of the pull request; they get lazy, so they quickly approve the pull request without giving it another thorough look.
After the pull request is merged, the product manager validates the changes in a staging environment and logs several bug tickets that the developer revisits in the next sprint cycle.
Now, let's look at an efficient code review process:
A developer is assigned to work on a new feature in Jira. They clarify the requirements with the product manager before breaking up the task into smaller subtasks.
After they complete the first subtask and all unit tests pass locally, they open a pull request. They read through their own code before requesting reviewers.
The reviewer promptly reviews the developer's changes. Since the pull request is small and manageable, they only have a few minor points of feedback. All linting and basic security checks are automated.
The developer is notified about the requested changes. They address the feedback right away, make sure that all tests again pass locally, and push their changes. The reviewer approves the pull request.
The developer merges the pull request. They continue on to the next subtask.
After all subtasks are completed, the task is automatically transitioned to quality review. The product manager validates that the changes work in a staging environment and marks the task as complete.
Inefficient code reviews are two-sided, causing pain for both the author and the reviewer. When the handoff between authors and their reviewers is slow or burdensome, both parties must put in more time and effort to get their changes approved and merged.
At the same time, trying to optimize for a fast code review cycle can have negative side effects. When a pull request isn't reviewed thoroughly -- when there is too much work in the queue, or if the pull request is so large that reviewers get overwhelmed -- issues are often overlooked. Martin Fowler summarizes this pain: "the unavoidable thing about waiting for approval is that it takes time. If too many changes are in the queue for feedback, either the quality of the feedback goes down or progress slows down."
Instead, the first goal of code reviews is to minimize the delay between handoffs: shortening the time for a reviewer to provide quality feedback and for a developer to receive that feedback.
When teams provide fast, high-quality feedback, they preserve context throughout the code review process — avoiding long gaps between feedback where authors and reviewers lose context.
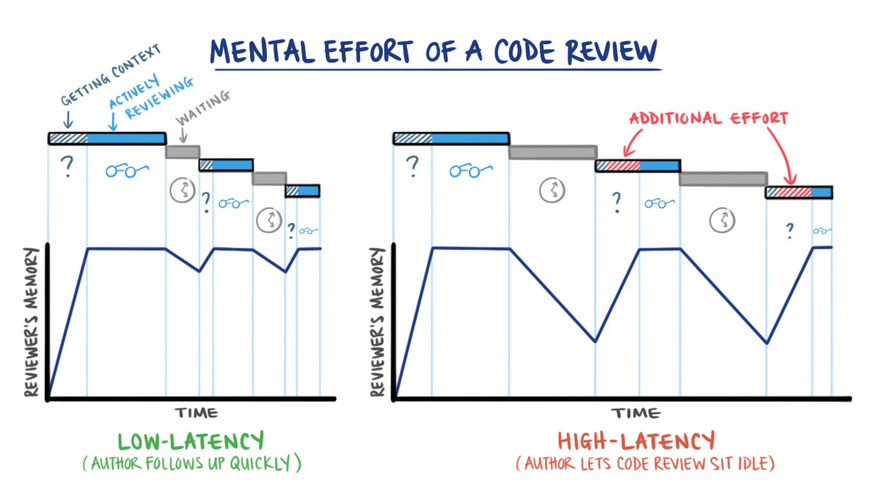
After teams shorten handoffs, the second goal of code reviews is scale: alleviating the choke points through which all changes must pass.
What works for a small team may not scale to a larger team. The complexity of code reviews scales as the team and codebase grows. Security requirements, release management processes, and dependencies between teams add overhead to the entire code review process.
Some might think the solution is mimicking the tech giants, but that's not enough. What works for Amazon or Facebook may actually be worse for a smaller team. As Jean Yang, founder of Akita Software, puts it:
A disproportionate amount of writing and tooling comes from companies like Facebook, Netflix, LinkedIn, Google, and Amazon. Many people assume there's a trickle-down effect: great engineers at companies with money to burn come up with good solutions to problems everyone has. But the solutions that engineers at a Netflix or LinkedIn or Facebook come up with aren't for the vast majority of software shops: they're often best for big companies that can afford to set a high engineering bar, that can afford large infrastructure teams and ops teams.
Instead, teams must be constantly iterating on their code review process. They must be process sizing, where they experiment with tools and processes to stay within their goals while measuring short and long-term trends to understand when and where to experiment again.
Ways to shorten feedback loops
To shorten feedback loops during the code review process, teams can experiment with pull request checklists, automated linters, and ephemeral Slack channels.
They can also make improvements to workflows before and after code reviews. As in the scenarios above, teams do a lot of work before opening a pull request that will affect the quality of code reviews, like running unit tests, or even before the task is started, like feature scoping. After the pull request is merged, developers follow their code after code reviews, ensuring it passes QA and is successfully deployed.
Measure time per stage
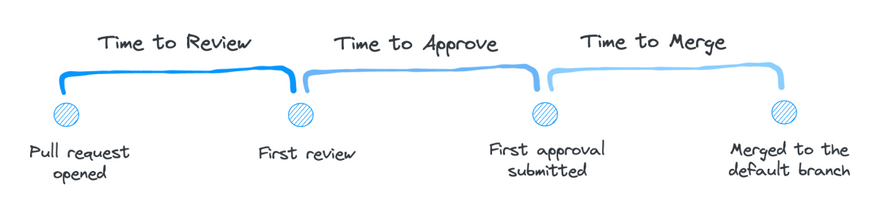
Measuring time spent reviewing code shows teams where their bottlenecks happen and how they can focus their experiments. There are three key stages that can be measured in a typical code review process:
Time to review: time between opening a pull request and the first review
Time to approve: time between the first review and first approval submitted
Time to merge: time between the first approval and merging those changes to the main branch
By providing visibility into these metrics, setting goals or working agreements for each stage, and measuring trends over time, teams can reduce the time to complete handoffs.
Automate manual tasks
Automating manual tasks in pull requests, such as linting, testing, and vulnerability detection, can streamline code reviews. For instance, setting up a linter like Rubocop for a Ruby on Rails app can save developers time commenting on formatting when reviewing code. Automating unit tests to run when a commit is made can save the author from forgetting to run tests locally and accidentally merging code that doesn't pass a test in a staging environment. Automations can also run in PRs to detect secrets that might have accidentally been committed.
Effective automation requires striking a balance between value and effort. Too much automation overburdens teams with technical and process debt. Too little automation leads to slow and unpredictable code reviews.
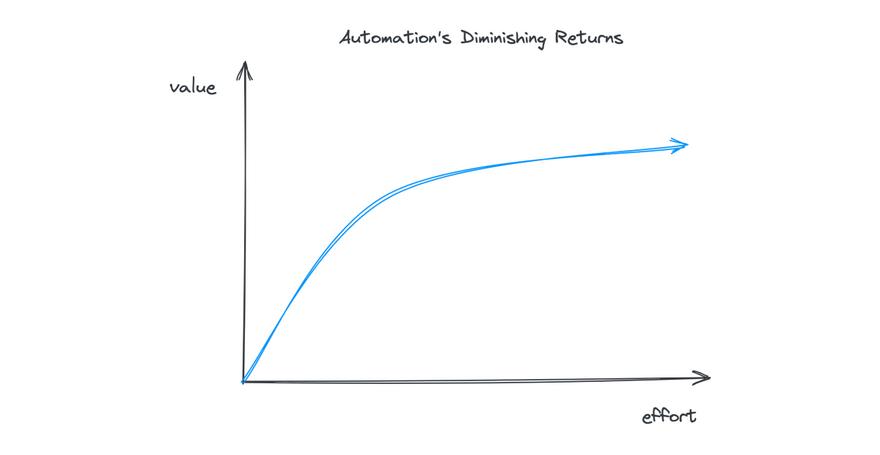
The net effect of both of these situations is developers spend less time on more important work. The amount of automation that is helpful is also dependent on team size; as the codebase becomes more complex, automation helps teams augment their code review process to protect developer time and share feedback faster.
Test early
The earlier things are tested, the better. When developers can run tests locally, verify small changes while they're coding, and see the results immediately -- rather than building up a backlog of unverified changes -- they save time later in the development cycle.
Testing too late can be especially time-consuming when there are many moving parts to integrate and test together. It can also lead to significant rework when developers need to make new changes all at once.
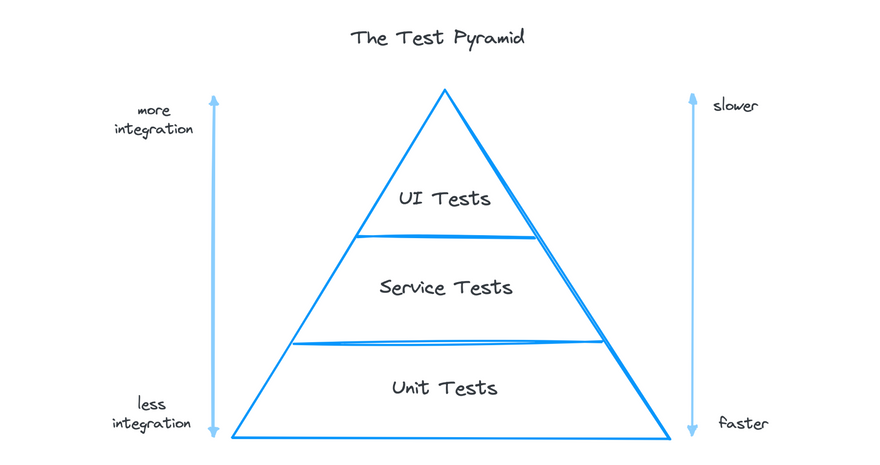
The time to validate changes locally is a feedback loop that teams can aim to optimize with unit testing. Similar to other types of automation, there's a tradeoff between speed and complexity. As a general rule of thumb, testing should be lightweight and fast early in the development process and more rigorous later on. This ensures big, complex tests don't fail on small issues, but still allows developers to frequently check their code with lightweight tests. Martin Fowler suggests a pyramid-shaped test suite:
Stick to the pyramid shape to come up with a healthy, fast and maintainable test suite: Write lots of small and fast unit tests. Write some more coarse-grained tests and very few high-level tests that test your application from end to end. Watch out that you don't end up with a test ice-cream cone that will be a nightmare to maintain and takes way too long to run.
When developers continuously test their changes before code reviews, their reviewers will work with higher-quality code. They can also focus on providing feedback, rather than running manual tests or nitpicking small changes.
Keep pull requests small and manageable
Smaller pull requests are typically easier to test, review, and merge to the main branch. They are less overwhelming for reviewers, so they can be reviewed more quickly and more thoroughly.
There is no magic number for the perfect size of a pull request. Some experts have suggested that reviewers should review fewer than 400 lines of code at a time, spending no more than an hour or so on each review session. Lines of code, however, are only a rough estimate of a pull request's size; many other factors impact its size, such as the number of files touched and the overall complexity of the changes.
To keep code reviews efficient, pull requests should encapsulate a single unit of work. Whereas large pull requests and long-lived feature branches often include many changes that need to be reviewed all at once, pull requests with a single unit of work are independent, incremental, and testable. Reviewers can better understand the goal of the changes and reason about how they will integrate with the rest of the codebase.
Small units of work may require teams to adopt trunk-based development, or a similar branching strategy that allows frequent merges to the main branch. Teams can also try stacking pull requests, sometimes known as 'chaining'. With stacked pull requests, developers 'share' code between branches by making them dependent on each other, allowing several people to work on a feature at the same time.
Make work in progress visible
Minimizing the time between review and changes is key to maintaining fast feedback loops. Yet code reviews sometimes fall to the wayside on busy days when developers move on to other tasks or lose track of work in progress.
By making work in progress more visible, teams can prioritize stale or aging pull requests that need their attention. GitHub offers some basic functionality around sorting pull requests by age or most recent updates, but there are a number of tools that can display the same information on a team dashboard or pull it up in a team Slack channel with a slash command. Teams can experiment with new ways of sharing updates with each other during code reviews, such as adding GitHub notifications to Slack.
Artem Sapegin, an engineer at Omio, also suggests making it clear when changes are ready for a re-review:
Every developer works differently: some will commit all the changes at once, some will commit each change separately. It's hard for a reviewer to know when you're done with all their feedback and ready for another iteration. Writing a short comment like "Ready for another iteration" will make it clear, and you'll get that another iteration sooner.
It's important for reviewers to stay in the loop throughout the code review process so pull requests don't become stuck or deprioritized behind newer work. If the time to a first review is short, but the time to approval is long, teams should focus on improving communication during re-reviews.
Dedicate time for reviews
A developer's time is split across many responsibilities. They write code, test their changes, and deploy them. They also update documentation, collaborate in meetings, and plan their team's projects each cycle.
Code reviews are often overlooked. It's hard to quantify and difficult to compare with other types of work. Code reviews also tend to be the first things replaced by other tasks when teams are under pressure or in a time crunch.
To restore balance to the code review process, teams can tweak two factors: the number of developers reviewing changes and the amount of time developers have available to review them.
More reviewers lead to fewer dependencies on specific people to approve changes. It also serves as a way to transfer knowledge across a team, so everyone on the team is better equipped to share feedback during code reviews. The result is developers have more team members available at any given point in time to provide feedback on their code.
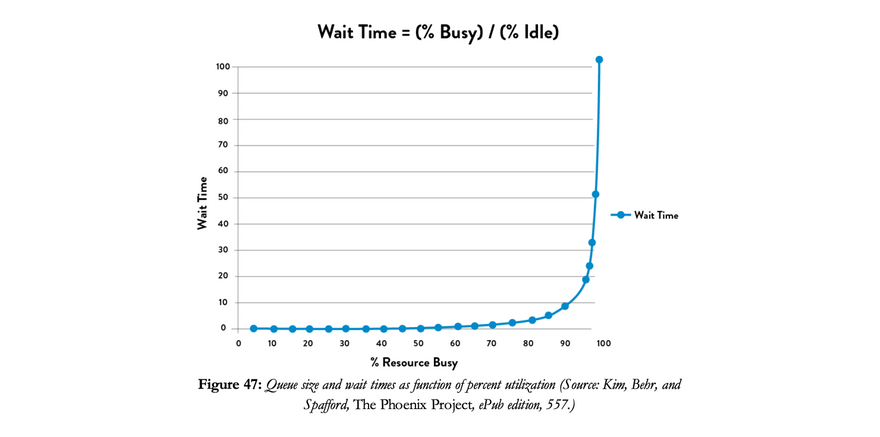
Setting aside sufficient time for reviewing code also creates a culture that values reviewing code as much as it does writing code. As developers become busier over the course of a project with less time to review others' code, the wait time for reviews tends to grow exponentially. Each handoff between author and reviewer takes longer and longer to resolve.
Gene Kim, in The Phoenix Project, suggests these handoffs can quickly become problematic:
The asymptotic curve shows why a "simple thirty-minute change" often takes weeks to complete — specific engineers and work centers often become problematic bottlenecks when they operate at high utilization. As a work center approaches 100% utilization, any work required from it will languish in queues and won't be worked on without someone expediting/escalating.
To reclaim time for code reviews, teams can try blocking calendar time, decreasing meeting load, or limiting work in progress.
Continuously review
When teams treat code reviews as a one-time hurdle to jump over rather than a continuous process, it puts pressure on both authors and reviewers to find and address every potential issue.
Teams can shift some of their review workload by continuously reviewing their code after integration. Martin Fowler refers to these post-integration code reviews as Refinement Code Reviews. They are triggered each time the code is looked at rather than when the code is added to the codebase:
A team that takes the attitude that the codebase is a fluid system, one that can be steadily refined with repeated iteration carries out Refinement Code Review every time a developer looks at existing code. I often hear people say that pull requests are necessary because without them you can't do code reviews — that's rubbish. Pre-integration code review is just one way to do code reviews, and for many teams it isn't the best choice.
Over the long-term, more frequent code reviews of production code can improve code quality and pay down technical debt. They also allow teams to mark changes during their traditional code reviews that should be addressed in the future, but are not necessarily blockers to merging a pull request.
Keep experimenting
There are many experiments teams can run to see what works best for their code review process. By better understanding their current bottlenecks, teams find the fastest way to move from an inefficient code review process to an efficient one.
What tools does your team use during code reviews? What workflows have improved your code reviews the most?

Top comments (0)